The date in server
Recently, I wanted to send a date from server to client and in client a Kendo grid to show as it is without applying local time zone.
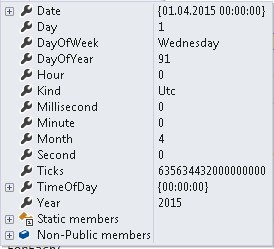
Let us try to understand date in server side in the world of C#. I have created a date using the below line. It is 1st April 2015 and tagging it as local date. When I say local date I mean the local date of the computer where this code is executing, that is the application server’s date. Obviously, the application server and browser can be located in two different time zones.

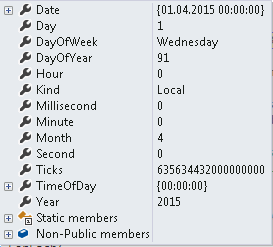
I could also say that the date is not local but UTC.

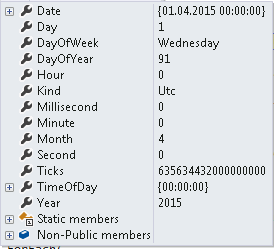
If we look at the two dates in details we see that both say it is 1st April 2015. We also see an important thing Ticks. This says the number of ticks since 0:00:00 UTC on 1st Jan, 0001. 1 millisecond = 10, 000 ticks.
This means no matter whether we say UTC or local the number of ticks remains the same till 1st April 2015 as long as we have a different attribute in C# DateTime object called Kind indicating what kind of date it is.
Apart from UTC and Local, there is a third Kind called Unspecified. If you are reading the date from say, database where the date read does not have any extra property for Kind it will be marked as Unspecified. Json would treat it as local Kind while creating a string. If you know that the date was indeed saved as UTC and if you want to mark it as a UTC date then the below function would do that without applying any time zone offset.

The date in client
Now that we have a C# date object with its Kind property we would like to pass this all the way to client as a JSON string. Let us use the Json function.

In client side, this is what we get for the first case where Kind property is local.

It returns the number of milliseconds since 0:00:00 UTC 1st Jan 1970 (epoch), also called ticks. What is important is to note that the string has no trace of Kind. What does it mean? This only means that the Kind is hardwired here. And that is UTC.
By the way, did you notice two important things? First, we lost the precision beyond milliseconds. And second, how it supports a date less than 1970, by using negative values. The numbers (Ticks and ticks) are different in server and in client. This is because both the starting time and the unit are different.
Now that we have the number of milliseconds elapsed since epoch we can easily get the date, both in UTC and local time in client side. How it will be rendered depends on how we do things in client side.
If we have the freedom to convert the time then we can show it however we want. Let’s first create the JavaScript date object from the string.

Now JavaScript date can support both UTC and local at once. The signature/value used to create the JavaScript object determines how the date will interpret the input. For example, in the above example, since we have initialized the date with number it will add that many milliseconds since epoch (UTC) and give a date. That date can be interpreted however we want.

toString prints it in local time and toUTCString prints in UTC.

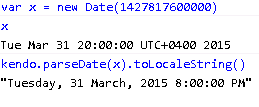
Note that the UTC date is no longer 1st April 2015. It is reduced by 8 hours and went back to 31st Mar 2015. This is because from server we sent 1st April 2015 in local kind (Server in Singapore time zone that is +8).
We can as well use Kendo functions and the output will be like below. The toLocaleString gives 12:00:00 AM. There is nothing to worry about here. If the time component is absent then the function assumes 12 AM midnight, essentially means the first moment of that day.

You might wonder why both the local date of server and the local date at client are the same. Well this is because both server and client are in the same time zone (Singapore +8).
Let us move the browser to a different time zone. Say, in the middle of UTC and Singapore (+8) to Moscow (+4). See the difference in number of milliseconds, the local date (server date is reduced by 4 hours and it moves to the previous day 8 PM, 4 hours short of server/Singapore local time).


The UTC time is still the same. It makes sense since our application server is still in Singapore and is still passing 1st April 2015 local. But why the toLocaleString() giving 7 PM? Should it not give 8 PM? Yes, it should and internet explorer does give 8 PM. I did run a new instance of chrome after changing the time zone to Moscow. And why does it say 7 PM, I have no clue. Both were using kendo version 2014.1.318. Let’s not get distracted here. Just say, oops and move on.
Internet explorer shows the below for this case. In my understanding that is correct.
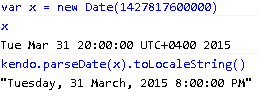
Had we sent the same date with UTC Kind would this still be the same? The answer is no. The number of milliseconds since epoch (UTC) would have been different for the same date of UTC Kind. They would have looked like below:


Note that the number of milliseconds since epoch is different and the date in UTC shows 1st April 2015.
Showing the date in Kendo grid in client
Let us assume that we have some columns and some rows to show in Kendo grid that includes some date columns. Some of those date columns should show the dates in UTC while the rest in local time zone.
So we send all these data as JSON string to client side and assign that data source to Kendo grid. In Kendo we have defined some date columns using code like
Type: “Date”
By default Kendo Grid would show the date in local time zone. That means it is going to apply the time zone offset on the string representing UTC date. Apparently, there is no way to simply indicate in the column definition to show the date in UTC.
That leaves us with only one option and that is to nullify the adjustment. If the browser in UTC -01:00, the 1st Apr 2015 00:00:00 is going to be shown as 31st Mar 2015 23:00:00. That means the date is reduced by 1 hour. So to nullify this effect, we will add 1 hour.


So the end result is that whatever date we send from server will be shown as it is no matter where the browser is located.
Sending the date back to server
The same thing happens when the date comes back. The date user picks is treated as local (browser) date. When we use say, kendo.stringify (converts JavaScript object to JSON) to serialize it before sending it to server then the date is converted to UTC.
Suppose user picks 1st April 2015 from Moscow that looks like below:

When it goes through kendo.stringify it looks like the below (4 hours reduced to make it UTC):
“2015-03-31T20:00:00.000Z”
So in server what we get is 31st Mar 2015 and not 1st April 2015. We lost where in the world this date came from (well, we can find it by some means but we are not talking about that here). So we cannot get back what user really chose.
Hence it is important that from client itself we nullify the serialization effect. We do this by adding 4 hours. Well we actually subtract the offset that is – 4 hours for Moscow. So when kendo.stringify converts the date to UTC during serialization it still remains 1st April 2015 and we get that in server.
“2015-04-01T00:00:00.000Z”
Is adjusting the offset enough?
Let us move our browser to Samoa that is 14 hours ahead from UTC (+14) during Local daylight saving time and UTC (+13) when day light saving time ends (on 5th April). 1st April 2015 would look like below:

If we get the time zone offset using today’s (say 18th April 2015) date as done above it would be – 13 hours. If we do the same with 1st April 2015, we would get – 14 hours.
Kendo.stringify would use the specific day’s offset and not today’s to make it UTC. Hence we have to get the offset of the day that user chose. If we use today’s offset then the adjustment won’t be correct and in server we will get the wrong date/time.
At this moment, you might be wondering was it correct to use today’s offset to adjust the UTC date that we got from server before passing it to Kendo.
The answer is No. We have to use the offset of that date. However that is a little bit tricky. Why? Well, how would we know the date in local time? In client we got the UTC date. That is the right date. We got to use the JavaScript UTC functions related to Date like getUTCFullYear() etc. to extract the year, month and day. Then create a local JavaScript date with those components. Get the time zone offset from that date and use that to adjust.
That is too much!
Can we get rid of day light saving time issue altogether?
We can either choose to adjust the way above or we ignore it altogether. How? When user chooses 1st April 2015, let us add 12 hours to that and make it 1st April 2015 12:00:00 PM. Take today’s time zone offset to adjust and that way we ignore that day light saving time.
When the date ends up in server in UTC, we outright set the date to 12 noon again and save that. It is the same story when the date makes it journey to client. There also use only today’s offset. Since we have 12 hours buffer, few hours’ fluctuation might change the time but not the date.
You might be interested in knowing a little issue here: if user manually types the date in Kendo date picker with a date based format the time is lost. The time is retained if calendar is used to input the same.
A few words on JSON date
We have seen two kinds of JSON dates:

“2015-04-01T00:00:00.000Z”
They are Microsoft’s ASP.NET built-in JSON format and ISO 8601 format respectively. Both would be treated the same way by Kendo. However the former is compatible with most browsers, especially the old ones.
Is this the right approach?
Well, adjusting the date in client side may not look good. It is not bad either. This is what Kendo is suggesting: adjust it at requestEnd function.
One way to handle this is to send string to client instead of date. However when Kendo would show them and we try to sort them the sorting will be based on the strings, not dates.
Another approach is to adjust the time zone offset in server side. When client request it for it let it pass the offset to it.
The best way would have been a flag while defining the Kendo column, especially in our case while the columns are dynamically decided, some of which would be dates, among them few would be in UTC and the rest in Local.
Index