
29th Friday Fun Session – 4th Aug 2017
Given a sequence of weights (decimal numbers), we want to find the longest decreasing subsequence. And the length of that subsequence is what we are calling weight loss score. This is essentially the standard longest increasing subsequence (LIS) problem, just the other way.
This is the solution to JLTi Code Jam – Jul 2017 problem.
Let us walk through an example
Let us take the example as mentioned here: 95, 94, 97, 89, 99, 100, 101, 102, 103, 104, 105, 100, 95, 90. The subsequence can start at any value, and a value in a subsequence must be strictly lower than the previous value. Any value in the input can be skipped. The soul goal is to find the longest subsequence of decreasing values. Here one of the longest decreasing subsequences could be: 105, 100, 95, 90 and the length would be 4.
Even though, in our weight loss example, we have to find the length of longest decreasing subsequence, the standard problem is called longest increasing subsequence. Essentially the problems are the same. We can have a LIS solution and can pass it the negative of the input values. Alternatively, in the algorithm, we can alter the small to large, greater than to smaller than etc. We chose the former.
We will use two approaches to solve this problem: one is a dynamic programming based solution having O(n2) complexity, another is, let’s call it Skyline solution having O(n log n) complexity.
Dynamic Programming Solution
Let’s work with this example: 95, 96, 93, 101, 91, 90, 95, 100 – to see how LIS would work.
When the first value, 95 comes, we know it alone can make a subsequence of length 1. Well, each value can make a subsequence on its own of length 1.
When the second value 96 comes, we know it is greater than 95. Since 95 already made a subsequence of length 1, 96 can sit next to it and make a subsequence of length 2. And it would be longer than a subsequence of its own of length 1.
When the value 93 comes, it sees it cannot sit next to any value that appeared prior to it (95 and 96). Hence, it has to make a subsequence of its own.
When the value 101 comes, it knows that it can sit next to any prior values (95, 96 and 93). After all, it is bigger than each of them. It then computes the score it would make if it sits next to each of them, separately. The scores would be 2, 3, and 2, if it sits next to 95, 96 and 93 respectively. Of course, it would choose 96. The subsequence is 95, 96, 101 and the score is 3.
So we see, we can go from left to right of the input, and then for each of the previous values, it sees whether it can be placed after it. If yes, it computes the possible score. Finally, it chooses the one that gives it the highest score as its predecessor.
So we are using the solutions already found for existing overlapping sub-problems (the scores already computed for its preceding input values, that we can reuse) and can easily compute its own best score from them. Hence, it is called a dynamic programming solution.
The following table summarizes it.
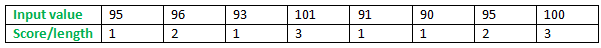
There are two longest subsequences each with length 3. For a certain value, if we need to know the preceding value, we can backtrace and find from which earlier value its score is computed. That way, we can complete the full subsequence ending with this value.
Since for each of the input values we are looping all the preceding values, the complexity is O(n2).
Skyline Solution
In this approach, we would retain all incompatible and hence promising subsequences since any of them could lead to the construction of one of the final longest subsequences. Only at the end of the input we would know which one is the longest. Since we are retaining all incompatible subsequences I am calling it Skyline, inspired by Skyline operator.
It is obvious but let me state here, all these solutions are standard, already found and used. However, Skyline is a name I am using as I find it an appropriate term to describe this method.
If there are two apples: one big and another small, and if you are asked to choose the better one, you would choose the big one. However, if you are given an apple and an orange, you cannot, as they are incomparable. Hence you need to retain both.
When a value comes it can be one of the below three types:
Smallest value (case 1)
- It won’t fit at the end of any existing subsequences. Because the value is smaller than all the end values for all existing subsequences.
- There is no other way but to create a new subsequence with this value.
- We can safely discard all single value subsequences existed so far. After all, the new subsequence with the smallest value can be compared with each of them and it is clearly superior to them (score for each such subsequence is 1 and the end (and only) value for the new one is the smallest – hence it can accept more future input values than the rests).
- In the list of subsequences we can retain the single value subsequence at first. Meaning, every time the new smallest value comes, we simply replace the existing smallest value listed as the first subsequence.
Biggest value (case 2)
- The opposite of the previous case is: the new value is bigger than the end values of each of the existing subsequences.
- So it can fit at the end of all existing subsequences. So which one to choose?
- Suppose, it is the end of the input. In that case, we would like it to go at the end of the longest subsequence found so far and make it longer by one more.
- However, if it is not the end of the input and suppose there are some future input values coming that are bigger than the end value of the present longest subsequence and smaller than the present input value. By placing the present input value at the end of the present longest subsequence we will jeopardize a more promising possibility in future.
- So we should rather copy the longest subsequence found so far and add this new value at the end of it, making it the new longest.
- At the same time, we retain the previous longest subsequence as it is, that by now is the second longest subsequence.
- We will add this new and longest subsequence at the end of the list.
Middle value (case 3)
- We have a third case where the input value can fit the end of some subsequences and cannot fit at the end of the rest subsequences.
- This is because this new value is bigger than the end values of some sun-sequences and smaller than the same for the rests.
- So which one to choose? Of course, we have to choose one where it can fit, meaning from those whose end values are smaller than the input value.
- And we would like to choose one with the largest end element (yet it is smaller than the input value).
- However, we cannot just over-write it for the same reason as stated earlier (case 2, promising reasoning). Rather we copy it, add the new value at the end of it and add it to the list.
- Where – at the end of the list?
- No, we would insert in next to the subsequence from which we copied and extended it.
- And we can safely discard all other subsequences with the same length as this newly created subsequence. After all, the length is the same and it’s end element is smaller than the end elements of the rests having equal length of it.
- Shall we run a loop over the list to find those to be deleted? No, we just need to find the next subsequence and if its length is the same as the newly created subsequence we delete it. No more checking is required.
- Why so? Please read the second point as stated below.
So we have handled all possible input values. The list of subsequences that we have created would have some nice properties:
- As we go from the first subsequence to the last in the list of subsequences, the length will gradually increase.
- There would be a maximum of one subsequence with a certain length.
- To find whether the input value is a case 1 or case 2 or case 3 type, we can easily run a binary search with O(log n) complexity over the end elements of the subsequences in the list. Since we would like to do so for each of the n input values, the complexity of this approach would be O(n log n).
- For doing the above we can use the list, just that we need to look at the end elements. Then why are we retaining the complete list?
- The answer is: to output the longest subsequence as well.
- Could we do it without saving the complete subsequence?
- We leave it for another day.
Walking through an example
Let’s go through the same example as used earlier: 95, 96, 93, 101, 91, 90, 95, 100.
95 (case 1)
95
96 (case 2)
95
95, 96
93 (case 1)
93
95, 96
101 (case 2)
93
95, 96
95, 96, 101
91 (case 1)
91
95, 96
95, 96, 101
90 (case 1)
90
95, 96
95, 96, 101
95 (case 3)
90
90 95
95, 96 (deleted)
95, 96, 101
100 (case 3)
90
90 95
90 95 100
95, 96, 101 (deleted)
Once all the input values are treated, the last subsequence would be the longest one.
GitHub: Scoring Weight Loss
