
22nd Friday Fun Session (Part 1) – 16th Jun 2017
We are trying to see how isolation level, serializable to be precise, can help us implementing a synchronization mechanism for web application.
Let us start with ACID
ACID stands for Atomicity, Consistency, Isolation and Durability. It is detailed in ISO standard. Database systems implement this so that a sequence of operations, called as transaction, can be perceived as a single logical operation.
Atomicity
All operations of a transaction are all done or nothing done. Logging with undo capability can be used to achieve this.
Consistency
Given that all database constraints (foreign key, unique etc.) are valid at the beginning, the same should be maintained, at the end of the transaction as well.
Durability
All changes done by a committed transaction must go to storage even if database system crashes in the middle. Logging with redo capability can be used to achieve this.
Why Logging?
We talked about logging and then redo/undo in the previous sections. Why Logging? Well, when some transactions changes data, they are not immediately written to disk. Rather those pages are marked as dirty. Lazy writing flushes them to disk later. Instant writing to disk is expensive. Instead, logging the operation that is directly written to disk immediately, is much cheaper.
However, performance, while important is not a must. Logging is essential to ensure atomicity and durability. Any modification must be written to log before applying to actual database. This is known as write-ahead logging (WAL) This is to make sure that in case of a crash (say, 2 out 5 operations of a transaction are written to database storage and then it crashes), system can come back, read the log and figure out what was supposed to be done and what was not supposed to be done. By redoing and undoing necessary operations, durability and atomicity is ensured.
Focus on the I of ACID
Today we focus on the I of ACID, called isolation. When we are writing a transaction, we write the operations inside it thinking nobody else is doing anything else to the data that we are dealing with. Isolation property defines such an environment and database systems implements that.
So, why do we need such an environment? Well, without this, in a highly concurrent transaction execution environment, our understanding of the data we are working with will not hold true, as other would change them simultaneously. It will happen largely due to three problems: dirty read, non-repeatable read, and phantom read.
However, creating such an isolated environment is expensive in terms of performance. Hence, a number of other isolation levels are introduced, giving various degrees of isolation rather than a complete isolation.
The ISO standard defines the following Isolation levels that we will describe in terms of two transactions T1 and T2 that executes in parallel.
Read Uncommitted
Transaction 1 (T1) updates salary for Joe Transaction 2 (T2) reads updated salary for Joe T1 aborts transaction
We see that, T2 read dirty (because T1 did not commit the updated salary) data and went ahead with his decisions/operations inside it based on it, that was of course a wrong thing it did.
As the name implies Read Uncommitted reads uncommitted data, also called dirty data that is wrong. So we see, this isolation level does not guarantee isolation property and it is an example of a weaker isolation level. Note that along with dirty read, it also has non-repeatable read and phantom read problems.
Read Committed
The next better isolation level, as the name Read Committed implies, reads only committed data and solves the dirty read problem encountered previously in Read Uncommitted isolation level. Let us see through an example. Now T1 is running in Read Committed isolation level.
T1 reads the salary of Joe T2 updates the salary of Joe and commits T1 reads the salary of Joe
So we see T1 reads the salary of Joe twice, and it is different in the two cases. In the second case, it reads the data that was modified and committed by T2. No more dirty read by T1. Good.
But the isolation property expects each transaction to happen in complete isolation, meaning it would assume it is the only transaction that is taking place now. Joe’s salary was not updated by T1. Then why should T1 see different data when it reads the second time?
So we see, T1 could not repeat a read (the same salary for Joe). Hence, this problem is called non-repeatable read. Read Committed, like Read Uncommitted is another weaker isolation level. Again, note that, along with non-repeatable read it also has the phantom read problem.
Repeatable Read
To solve the non-repeatable read problem, Repeatable Read isolation level comes into picture. Since T1 reads the salary of Joe, no other transaction should be able to modify Joe’s data if we run T1 in Repeatable Read isolation level.
If we repeat the previous transactions we did earlier we would see T2 waits for T1 to finish first. Because T1 would use the right locks on the rows it reads so that others cannot delete/modify it. Repeatable read is solving the non-repeatable read problem as the name implies.
However, that won’t stop new data insertion. After all, Repeatable Read put necessary locks only on the data that it has read, not on future data. Hence, we will see ghost/phantom data. Let’s see an example.
T1 reads 4 rows in employee table T2 inserts one record in employee table and commits T1 reads 5 rows in employee table
We see that T1 sees a phantom row (the newly inserted row by T2) in its second read of employee table. Repeatable Read, once again, another weaker isolation level.
Serializable
So far, we see different isolation levels providing different degrees of isolation level but not what I of ACID really defines as isolation. We also know that weaker isolation levels are introduced to avoid the performance penalty that occurs for executing transactions in complete isolation. But at times, it becomes an absolute necessity to execute transaction in full isolation. Serializable comes into picture to implement that complete isolation. In serializable isolation level, it is ensured that we get the effect as if all transactions are happened one after another, in the order they started.
So if we rerun the earlier two transactions, we would see T2 waiting for T1 to complete first. Hence both the reads of T1 would read 4 rows. Only after T1 is done that T2 would insert a new row.
This solves all the three problems: dirty read, non-repeatable read and phantom reads.
At this point, it can be mentioned here that ISO standard expects serializable, not serial. The end result of a serializable execution is to produce a result equivalent to executing them one after another. Serializable does not necessarily executing transaction one after another, just that the end result is the same, had they executed serially.
MS SQL Server implementation
With Serializable, we are done with the 4 ISO transaction isolation levels. MS SQL Server implements all of them. In addition, it implements a fifth one, called Snapshot.
Snapshot
It is an isolation level that solves all the three problems just like serializable. So, why do we have two isolation levels doing the same thing? What special thing snapshot is doing?
If we closely observe the earlier serializable isolation level, implemented using locks, we see that it is too pessimistic. T2 has to wait for T1 to finish. But T2 could be simultaneously executed. After all, T1 is only reading, not modifying any data.
Snapshot comes into picture with optimistic concurrency control. It uses multiversion concurrency control (MVCC) to implement this. Every transaction starts with the latest committed copy it sees and keeps on executing the operations inside it.
So, for the last example we saw, in snapshot, T1 would read 4 rows in both the reads. After all, it had its own private copy. On the other hand T2 would start with its own copy, add a row in the middle. At the end, it would see there was no conflict. This is because no other transaction, T1 in this case, did anything conflicting. So, two transactions are simultaneously executed without violating the requirements of a serializable solation level.
What would happen if both T1 and T2 modify the same data, creating a conflicting situation? Well, both the transaction started with its own copy hoping that at the end there would no conflict, hence it is called optimistic. But if there is a conflict, the one committed first would win. The other would fail and rollback.
By the way, even though it is called serializable, write skew, anomaly is still present and it cannot be called serializable in ISO definition.
Database needs to be configured, which at times takes a while, to use this isolation. Again, since each transaction uses its own private copy, it is resource intensive.
At a glance
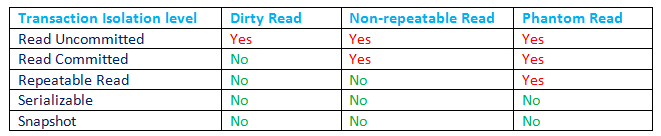
Default transaction isolation level for MS SQL Server
Read Committed is the default isolation level set for MS SQL Server. Keeping performance in mind, it is done this way. So all along if you had thought, by default, you were getting the I of ACID by SQL Server, you are wrong. You are living with non-repeatable read and phantom read unless you have explicitly changed the isolation level or used locks.
How to set isolation level in MS SQL Server?
We can set one isolation level at a time using the following command:
SET TRANSACTION ISOLATION LEVEL
{ READ UNCOMMITTED
| READ COMMITTED
| REPEATABLE READ
| SNAPSHOT
| SERIALIZABLE
}
[ ; ]
As mentioned earlier, to set snapshot isolation level some database specific configuration is required before executing the above command.
How long isolation level remains active?
Once set, it lasts for the session, the duration of which is largely controlled by the component that creates it. When another session starts, it starts with the default Read Committed.
Transaction
It is obvious yet important to remember, isolation levels works on transaction. After all, it is called transaction isolation level. If we want to isolate (using isolation level) the execution of a set operation as a single logical operation, then they have to be wrapped with Begin and Commit transaction.

“Lazy writing flushes them to disk later. Instant writing to disk is expensive. Instead, logging the operation that is directly written to disk immediately, is much cheaper.”
What happens with advances these days w.r.t and in memory db`s
I was not complete there. Performance is important but not the only reason. Logging before writing to disk is necessary for atomicity and durability. System can crash in the middle of directly writing to disk. Hence Write-ahead logging (WAL) ensures that, any change is written to log before applying to the actual system. In case a crash, database system can come back and check what was supposed to be done and accordingly recover from the crash by redoing/undoing. https://en.wikipedia.org/wiki/Write-ahead_logging
Thank you for your comments. I am editing the post.
Snapshot isolation can be made serializable! See for instance
Click to access srevilak-dissertation.pdf