
53rd Friday Fun Session – 9th Mar 2018
What Does Collation Do in SQL Server?
Collation in SQL server does two things:
- Storage: specifies the character set/code page used to store non-Unicode data
- Compare and sort: determines how to compare and sort all textual data
No Bearing on Code Page of Unicode Data
Code page as specified in a collation is applicable only for non-Unicode characters. Unicode data is stored using UCS-2/UTF-16 character set (UCS-2 is a predecessor of UTF-16), code page 0, irrespective of what collation is in use. So collation has no bearing on the storage of nvarchar, nchar etc. type (Unicode) data.
Many Code Pages
Apart from code page 0 that is used for Unicode data, there are 16 other code pages for storing non-Unicode data.
SELECT name, COLLATIONPROPERTY(name, 'CodePage') AS [Code Page], description FROM ::fn_helpcollations()
Each of the around 3885 collations, as I can see in SQL Server 2012, uses one of these 17 code pages. As said, even when a collation uses one of those 16 non-Unicode code pages, for Unicode data (nvarchar etc.), code page 0 will always be used. Code page for Unicode data is not configurable. However, around 510 collations use code page 0. For them, even for non-Unicode data like varchar, code page 0 will be used.
Two Parts of a Collation Name
A collation name looks like SQL_Latin1_General_CP1_CI_AS. The first part indicates the (language and) code page. The later part CI, AS etc. indicates compare/sort rules.
No Bearing on Compare/Sort for Non-textual Data
Collation affects only textual data as far as comparing/sorting is concerned. Non-textual data like integer, date, bool, decimal etc. are not affected.
Options Associated with Collation
All the options as listed below dictate sorting preferences.
- Case-sensitive (_CS) – ABC equals abc or not.
- Accent-sensitive (_AS) – ‘a’ equals ‘ấ’ or not.
- Kana-sensitive (_KS) – Japanese kana characters (Hiragana and Katakana) sensitivity
- Width-sensitive (_WS) – full-width and half-width characters sensitivity
- Variation-selector-sensitive (_VSS) – related to variation selector of Japanese collations.
Collation Sets
There are many collations that can be used in SQL Server. They are broadly divided into three categories:
- SQL collations
- Windows collations
- Binary collations
SQL Collations
SQL collations use different algorithms for comparing Unicode and non-Unicode data. Let’s us understand using an example.
Suppose SqlDb database, as used for the below example, using SQL_Latin1_General_CP1_CI_AS (CP1 stands for code page). NameU column uses nvarchar (Unicode) while NameNU column uses varchar. Sorting on them produce two different sets of results as shown below.
SELECT [Id], [NameU], [NameNU] FROM [SqlDb].[dbo].[Test1] ORDER BY [NameU]

ab comes before a-c when sorting is done based on the Unicode column.
SELECT [Id], [NameU], [NameNU] FROM [SqlDb].[dbo].[Test1] ORDER BY [NameNU]

On the other hand a-c comes before ab when sorting is done based on the non-Unicode column.
Windows Collations
Windows collation, introduced in SQL Server 2008, uses the same algorithm for comparing both Unicode and non-Unicode data.
SqlDbU database as used below is using Windows collation Latin1_General_CI_AS. Using the same table definition and same queries as earlier, we see that both result sets are the same unlike earlier.
SELECT [Id], [NameU], [NameNU] FROM [SqlDbU].[dbo].[Test1] ORDER BY [NameNU]

ab comes before a-c when sorting is done based on the Unicode column. So we see sorting results on Unicode data remain the same in both SQL and Windows collation.
SELECT [Id], [NameU], [NameNU] FROM [SqlDbU].[dbo].[Test1] ORDER BY [NameU]

Once again, ab comes before a-c when sorting is done based on the non-Unicode column.
Consistent Sorting Behavior across Database and Application
One more good thing about Windows collation is that, if it is used then sorting behavior is consistent with other applications running in a computer using the same local settings.
After all, “Windows collations are collations defined for SQL Server to support the Windows system locales available for the operating system on which SQL Server instances are installed.”
For new SQL Server installation Windows collation is recommended.
Difference at a Glance
Difference between a SQL collation and its equivalent Windows collation can also be seen from the description column of the below query result.
SELECT
name,
COLLATIONPROPERTY(name, 'CodePage') AS [Code Page],
description
FROM ::fn_helpcollations()
WHERE name IN ('Latin1_General_CI_AS', 'SQL_Latin1_General_CP1_CI_AS')

As we see, (inside SQL Server) the only difference being how the sort/compare would happen for non-Unicode data.
Comparing/Sorting Unicode
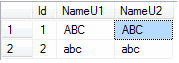
Comparing/sorting results for Unicode data remain the same in equivalent (language and option being the same) SQL and Windows collation. But they will vary when options are different. In the below example, Both NameU1 and NameU2 columns are using nvarchar (Unicode) data type. But they are using two different collations having different options – the first is using a case-sensitive collation while the latter is using a case-insensitive one. Output will be based on collation option and hence they will differ.
SELECT [Id], [NameU1] -- uses SQL_Latin1_General_CP1_CS_AS, [NameU2] -- uses SQL_Latin1_General_CP1_CI_AS FROM [AbcSU].[dbo].[Test1] ORDER BY [NameU2]
If we ORDER BY column NameU1 that is using a case-sensitive collation, we see the below result.

If we ORDER BY column NameU2 that is using a case-insensitive collation, we see the below result (following the same order as the data inserted into the table).
How to Set Collations
Collations can be set at server, database, and column level. Apart from that, it can be used in an expression to resolve two different collations.
Server Collation
There is a server level collation. Once set during installation, changing it would require dropping all user databases first (after generating database creation script, export data etc.), rebuilding master database etc., recreate the user database and import the data back.
Database Collation
By default, when a user database is created, it inherits server’s collation. However, it can specify its own collation as well. That way, each database can have its own collation. Database collation is the default for all string columns, temporary objects, variable names and other strings in the database. We cannot change the collation for system databases.
Once a database is created, collation for it can be further changed. However, we need to take care as to how the possible code page change would affect the existing data. Also, how the option changes, if any, would produce different query/join result.
Column Level Collation
Down the line, collation can be specified at column level (of a table). Same concerns, as to how the existing data would behave, have to be addressed.
Expression Level Collation
Collation can be specified at expression level as well – for example, to join two columns belonging to two different collations that SQL Server would otherwise complain.
Changing Collation Changes Meaning of Underlying Data
If collation is changed for a column/database, underlying code page might also change. If it differs, the new collation might render an existing char as something different in the new collation. For example, a character represented by code 100 remains the same at storage – still 100, with changing collation, but the mapped char in the new collation might be different.
For Unicode data, output/mapping remains the same. After all, there is just one code base for them.
As far as compare/sort is concerned, some of the things might change. For example, result of a query that uses a sort on a textual column may change if one of the collation options, say case-sensitivity changes. The same might affect the cardinality of a sort result. A sort result that was earlier producing a certain number of rows can produce more or less rows now.
Safe Collation Change
However, as far as changing a SQL collation to a Windows collation (or vice versa) is concerned, as long both the collation options remain the same and if the database is using only Unicode data (nvarchar etc.), it is quite safe. The below query can be used to find what all data types are used in the database table (and view) columns.
SELECT *--distinct(DATA_TYPE) FROM INFORMATION_SCHEMA.COLUMNS WHERE DATA_TYPE = 'varchar'
Temp Table Issues
One particularly common problem that arises from the difference in collation is to deal with temp tables. When collation of a database varies from its server’s collation, the temporary tables it creates use a different collation (server’s collation) from it. After all, temp tables are created in tempdb database and this system database follows the server’s collation. Temp table with a different collation than the database that created it works fine on its own. However, if say a join (on textual column) is required between that temp table and a table in the user database, and that is often the case, then SQL Server would complain as the collations of the two columns are different.
To avoid this issue, when temp table is defined, it is safe to specify the right (same as the database creating it with which it would do a join later) collation, for its textual columns.
Address nvarchar(10) COLLATE Latin1_General_CI_AS NULL;
Alternatively, while joining two columns belonging to different collation, we can specify what collation should be used (collation in expression).
Suppose, #T1 is using Windows collation Latin1_General_CI_AS while T2 is using SQL collation SQL_Latin1_General_CI_AS. If we want the join to take place using SQL collation then we will use the below query.
SELECT * FROM T1 INNER JOIN T2 ON #T1.field COLLATE SQL_Latin1_General_CI_AS = T2.field
