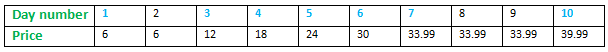Given the stock prices for a number of days, in order, we have to buy one stock at one day and then sell it on a later day to maximize the profit.
This is the solution to JLTi Code Jam – May 2017 problem.
Let us walk through an example
Suppose, we have 8 days’ stock prices, starting at day 1, in order and they are 2, 10, 5, 12, 1, 3, 11, and 9 respectively. We can clearly see, if we buy a stock at day 1, at a price of 2 and then sell it on day 4, at a price of 12; we can make a profit of 10. We could make the same profit had we bought it on day 5, at a price of 1 and then sold it on day 7, at a price of 11. Since we want to make the most profit only once, we would choose say, the first one.
Accumulator pattern
We could simply run two loops, consider all possible buys and sells, calculate all possible profits (like buy on day 1 and sell it on day 2 with profit 8, buy on day 1 and sell it on day 3 with profit 3, and so on) and find the maximum profit. The below code using accumulator pattern – traverse a sequence and accumulate a value (here it is maximum), as it goes, can be used to do so.
void StockN2(double price[], int n, double &maxProfit, int &buyDay, int &sellDay)
{
for(int i=0; i<n; i++)
for(int j=i+1; j<n-1; j++) { if(price[j] - price[i] > maxProfit)
{
maxProfit = price[j] - price[i];
buyDay = i;
sellDay = j;
}
}
}
For the outer loop that runs (n-1) times the inner loop runs (n-1) times resulting in O(n2), also known as quadratic complexity. Can we do better?
Divide and conquer solution
When we have an algorithm with O(n2) complexity, and we think about optimizing it, we ask ourselves – what could be better than this. And then O(n log n) comes to our mind. Even though there are many other complexities in between these two, usually O(n log n) is next best after O(n2). And when we see log n, divide and concur comes to our mind.
If we use divide and conquer, we have to divide the input into two sets, find some kind of solutions from both sides and then combine them. What decision can be found from two sides? We can get the maximum profit from each of the two sides. For example, suppose, we have only 4 days’ stock prices: 2, 10, 5 and 12. If we divide them into two, we would get left side: 2 and 10. Right side: 5 and 12. Left side profit would be 8 and the same for right side would be 7. The best between the two would be 8.
However, we can clearly see that the maximum profit is not 8, but 10 when the buy happens in left and sell happens in the right side. It is understandable that local solutions from left and right sides alone would not result in a global optimal solution. Somehow we have to compute a third profit combining the two sides. It is also obvious that buy happens in the left side and sell happens in the right side (after all, we cannot sell before we buy). So we see that the merge phase of the divide and conquer should consider the below 3 profits and find the best among them.
- Maximum profit from left side
- Maximum profit from right side
- Profit by buying at the lowest from left and then selling at the highest in right
The below code is doing this. By the way, we are not tracking the buy day and sell day to keep the focus on the main points. Buy day and sell day can be easily accommodated.
void StockDivideAndConquerNlogN(double price[], int start, int end, double &maxProfit)
{
if(start == end)
{
// just one value, return
maxProfit = 0;
return;
}
int mid = start + (end-start)/2;
double leftMaxProfit;
StockDivideAndConquerNlogN(price, start, mid, leftMaxProfit);
double rightMaxProfit;
StockDivideAndConquerNlogN(price, mid+1, end, rightMaxProfit);
double minLeft = GetMin(price, start, end);
double maxRight = GetMax(price, start, end);
double minValue = GetMin(price, start, mid);
double maxValue = GetMax(price, mid+1, end);
maxProfit = maxOutOfThree(leftMaxProfit, rightMaxProfit, maxValue - minValue);
}
For our working example, with 8 days’ stock prices, it looks like below:

The value inside the circle indicates the profit. It is coming from the best of the three as detailed earlier.
Computing complexity
How much is the cost? To compute it, we have to find two things – how many levels and how much work is done at each level.
How many levels? We have 8 items. At each level, it is halved. 8 -> 4 -> 2 -> 1. Suppose, in general, we are halving it k times. That means, n is divided by 2, k times. That means, n is divided by 2k and then it becomes 1. 1 = n/2k => n = 2k => log n = k log 2. Since, log 2 = 1, base being 2, k = log n. For n = 8, k = 3.
Level starts at 0 (the root) and ends at k. Hence, the actual number of levels is k+1. For simplicity, the rest of the post would consider the total number of levels to be log n, ignoring the small constant issue of 1.
Next thing to find: how much work is done at each level. We see, at each level, minimum is found from left, costing n/2 and maximum is found from right, also costing n/2. At each level, merging them (computing the third profit and then finding the best among the three) costs iterating n items and a few constant comparisons. Note that, at each level, all n items are present. It is the number of total processed items from all the sub-problems present in that level, not necessarily just from two sub-problems. So for log n levels the total cost is (n * log n) = n log n.
This calculation is explained/performed using master theorem.
Optimized divide and conquer solution
At each level, we are running loops and iterating n items to get the minimum from left and maximum from right. This loop is not necessary. The minimum and maximum can be computed bottom up doing a constant number of comparisons, at each level.
The below code shows this optimized version:
void StockDivideAndConquerOptimizedN(double price[], int start, int end, double &maxProfit, double &minValue, double &maxValue)
{
if(start == end)
{
// just one value, return
maxProfit = 0;
minValue = maxValue = price[end];
return;
}
int mid = start + (end-start)/2;
double leftMaxProfit, leftMinValue, leftMaxValue;
StockDivideAndConquerOptimizedN(price, start, mid, leftMaxProfit, leftMinValue, leftMaxValue);
double rightMaxProfit, rightMinValue, rightMaxValue;
StockDivideAndConquerOptimizedN(price, mid + 1, end, rightMaxProfit, rightMinValue, rightMaxValue);
maxProfit = maxOutOfThree(leftMaxProfit, rightMaxProfit, rightMaxValue - leftMinValue);
minValue = leftMinValue > rightMinValue ? rightMinValue : leftMinValue;
maxValue = leftMaxValue > rightMaxValue ? leftMaxValue : rightMaxValue;
}
Computing complexity for this optimized version
In this optimized version, for each of the log n levels, we are still doing some processing. It is no longer n items. Rather, the number of items is decreasing by half at each level, upwards. At the bottom-most level there are n items. One level up, it is reduced by half (due to the merging), shrinking to n/2 items. As it goes up, it gets reduced and at the topmost level it becomes only one item. Let us add the items from each level that we we processing.
n + n/2 + n/22 + n/23 + n/24 + . . . . + n/2k)
=> n (1 + 1/2 + 1/4 + 1/8 + . . .)
=> n * 2 (the convergent series gives 2)
=> 2 n
By discarding the constant terms, we get a complexity of O(n), meaning we can get the maximum profit in linear time.
GitHub: Stock Profit
Index