47th Friday Fun Session – 19th Jan 2018
We have seen why Dijkstra’s algorithm cannot work with negative edge and that we cannot trivially add a constant to each of the edge weights and make them non-negative to proceed further. It is where Johnson’s algorithm comes into play. It finds a special set of offset values to remove the negative edges (change the negative edge weights to non-negative edge weights) and now this transformed graph is all set to work with Dijkstra’s algorithm.
How Does Johnson’s Algorithm work?
Johnson’s algorithm starts with a graph having negative edge(s). Let’s go through it using an example as shown below.

Add a New Node
It then adds a new vertex, let’s call it s, with edges starting from it and ending to each of the vertices of the existing graph, each having a cost of 0, as we have done earlier.

Apply Bellman-Ford
Then it applies Bellman-Ford, a Single Source Shortest Path (SSSP) algorithm that can work with a graph having negative edge(s). We will use s as the source, and find shortest path from it to all other vertices.
We also need to check whether a negative cycle exists, something that Bellman-Ford can detect. If it exists then we cannot proceed further as we cannot find shortest path in a graph with negative cycle. In our example graph, there is no negative cycle.
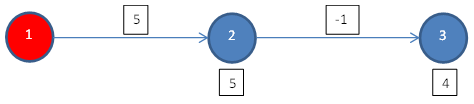
We find d[s, 1] = 0, d[s, 2] = -30, and d[s, 3] = 0 as shown below, using this code where d[s, t] indicates the shortest path from s to t.

Adjust Original Edge Weights
Now using these shortest path costs, original edges will be updated using the formula: w’[u, v] = w[u, v] + d[s, u] – d[s, v]. Applying the same for the original 3 edges in the original graph, we find,
w’[1, 2] = w[1, 2] + d[s, 1] – d[s, 2] = 20 + 0 – (-30) = 50
w’[1, 3] = w[1, 3] + d[s, 1] – d[s, 3] = 40 + 0 – 0 = 40
w’[3, 2] = w[3, 2] + d[s, 3] – d[s, 2] = (-30) + 0 – (-30) = 0
Now that we have adjusted the original edge costs, the new (cost) adjusted graph (without s and associated edges) does not have any more negative edge. Let’s see how the cost adjusted graph looks like.

Apply Dijkstra
With this non-negative edge graph we can proceed with Dijkstra’s algorithm. For each shortest path found in this graph from u to v, we have to adjust back the cost by subtracting d[s, u] – d[s, v] from it.
Is the Shortest Path Still the Same?
We are adjusting edge cost to remove negative edge. That way, we are changing the graph to some extent. However, while doing so we must preserve certain things of it. What was the cheapest cost in the original graph must still remain the cheapest path in the transformed graph. Let’s first verify whether that is indeed the case.
We will first look at the original graph (before edge cost adjustment). Let’s take a certain source destination pair (1, 2). There are two paths to reach from vertex 1 to vertex 2.
The first one (original):
d1[1, 2]
= from vertex 1 to vertex 2 directly using edge 1->2
= 20.
The second one (original):
d2[1, 2]
= from vertex 1 to 3 and then from 3 to 2
= 40 + (-30)
= 10.
Now let’s see how the costs of the same two paths change in the new cost adjusted graph.
The first one (cost adjusted):
d’1[1, 2]
= from vertex 1 to vertex 2 directly using edge 1->2
= 50.
The second one (cost adjusted):
d’2[1, 2]
= from vertex 1 to 3 and then from 3 to 2
= 40 + 0
= 40.
We see both the path costs have increased by 30, a constant. So what was earlier the shortest from vertex 1 to vertex 2, in the original graph, which was the second path, using two edges: edge 1->3 and edge 3->2, still remains the shortest path in the cost adjusted graph.
So how did that happen? Let’s have a closer look as to how the path cost changes.
The first one (cost adjusted):
d’1[1, 2]
= w’[1, 2]
= w[1, 2] + d[s, 1] – d[s, 2]
= d1[1, 2] + d[s, 1] – d[s, 2]
The second one (cost adjusted):
d’2[1, 2]
= w’[1, 3] + w’[3, 2]
= w[1, 3] + d[s, 1] – d[s, 3] + w[3, 2] + d[s, 3] – d[s, 2]
= w[1, 3] + d[s, 1] + w[3, 2] – d[s, 2]
= w[1, 3] + w[3, 2] + d[s, 1] – d[s, 2]
= d2[1, 2] + d[s, 1] – d[s, 2]
So we see both the paths, with a certain source u and a certain destination v, have increased with a constant cost = d[s, u] – d[s, v], where s is the extra node that we added before applying Bellman-Ford algorithm.
We can easily find, no matter how many paths are present between a certain source s and a certain destination v, and no matter how many edges each of those paths uses, each of them would be adjusted by adding a constant cost = d[s, u] – d[s, v] to it. And hence, the shortest path in the original graph remains the shortest path in the new cost adjusted, non-negative edge graph.
Let’s consider a path that goes through 5 vertices: u, x1, x2, x3, and v.
In the cost adjusted graph the cost
d’[u, v]
= w’[u, x1] + w’[x1, x2] + w’[x2, x3] + w’[x3, v]
= w[u, x1] + d[s, u] – d[s, x1] + w[x1, x2] + d[s, x1] – d[s, x2] + w[x2, x3] + d[s, x2] – d[s, x3] + w[x3, v] + d[s, x3] – d[s, v]
= w[u, x1] + d[s, u] + w[x1, x2] + w[x2, x3] + w[x3, v] – d[s, v]
= w[u, x1] + w[x1, x2] + w[x2, x3] + w[x3, v] + d[s, u] – d[s, v]
= d[u, v] + d[s, u] – d[s, v]
By generalizing the above, we see that a constant cost d[s, u] – d[s, v] is getting added to all paths from u to v.
Are all Negative Edge Removed?
The second thing that we need to prove is: no longer there exists a negative edge in the adjusted graph. After applying Bellman-Ford, we computed the shortest paths from source s. Let’s assume, d[s, u] and d[s, v] are the shortest paths from s to any two vertices, u and v, respectively. In that case, we can say,
d[s, v] <= d[s, u] + w[u, v]
=> 0 <= d[s, u] + w[u, v] – d[s, v]
=> 0 <= w[u, v] + d[s, u] – d[s, v]
=> 0 <= w’[u, v]
We prove that the new edge cost, w’[u, v] is always non-negative.
Why Would We Use Johnson’s algorithm?
So here with Johnson’s algorithm, first we use Bellman-Ford to get a set of values; using which we transform the graph with negative edge to a graph with all non-negative edges so that we can apply Dijkstra’s algorithm.
But why would anyone want to do that? After all, both Bellman-Ford and Dijkstra are SSSP algorithms. What is the point of using one SSSP algorithm to transform a graph so that another SSSP algorithm can be used on the transformed graph?
Dijkstra’s Algorithm is Faster
Well, the reason being, the latter SSSP algorithm, namely Dijkstra’s, is much faster than Bellman-Ford. So, if we need to find shortest paths many times, then it is better that first we apply a bit more expensive SSSP alogorithm – Bellman-Ford to get the graph ready to work with Dijkstra’s algorithm. Then we execute much cheaper Dijkstra’s algorithm on this transformed graph, as many times as we want – later.
Sparse Graph
But in such a situation is it not better to run an ALL-Pairs Shortest Paths (APSP) algorithm like Floyd-Warshall? After all, Floyd-Warshall can compute APSP at a cost of O(V3) while Bellman-Ford costs O(|V| * |E|) that can shoot up to O(V3), when E=|V|2 for a dense graph.
Yes, that is correct. For a dense graph Johnson’s algorithm won’t possibly be useful. Johnson’s algorithm is preferable for a sparse graph when Bellman-Ford is reasonably efficient to work with it.